1️⃣MongoDB 란?
MongoDB는 오픈소스 비관계형 데이터베이스 관리 시스템(DMBS)이며, NoSQL, Document 지향 데이터베이스
데이터를 배열 및 중첩 Document와 같은 복잡한 데이터 유형을 효율적으로 저장할 수 있는 유연한 JSON과 유사한 형식인 BSON(Binary JSON)으로 저장
2️⃣MongoDB의 데이터 구조
● Document
○ MongoDB에서의 가장 기본 데이터 단위 = 관계형 데이터베이스의 행
○ JSON과 유사한 BSON 형식으로 저장됨
{
"_id": ObjectId("603d1b2f5f3a1d2d4c4b9f04"),
"name": "Alice",
"age": 25,
"skills": ["JavaScript", "Node.js", "MongoDB"]
}
● Collection (컬렉션)
○ RDBMS 의 테이블에 해당
○ 같은 유형의 문서(Document)들을 저장하는 그룹
○ 스키마(Schema)가 고정되어있지 않아 문서마다 필드 구조가 달라도 됨
● Database (데이터베이스)
○ 여러 개의 컬렉션(Collection)을 포함하는 MongoDB 최상위 데이터 단위
○ 여러 개의 데이터베이스를 하나의 MongoDB 인스턴스에서 관리 가능
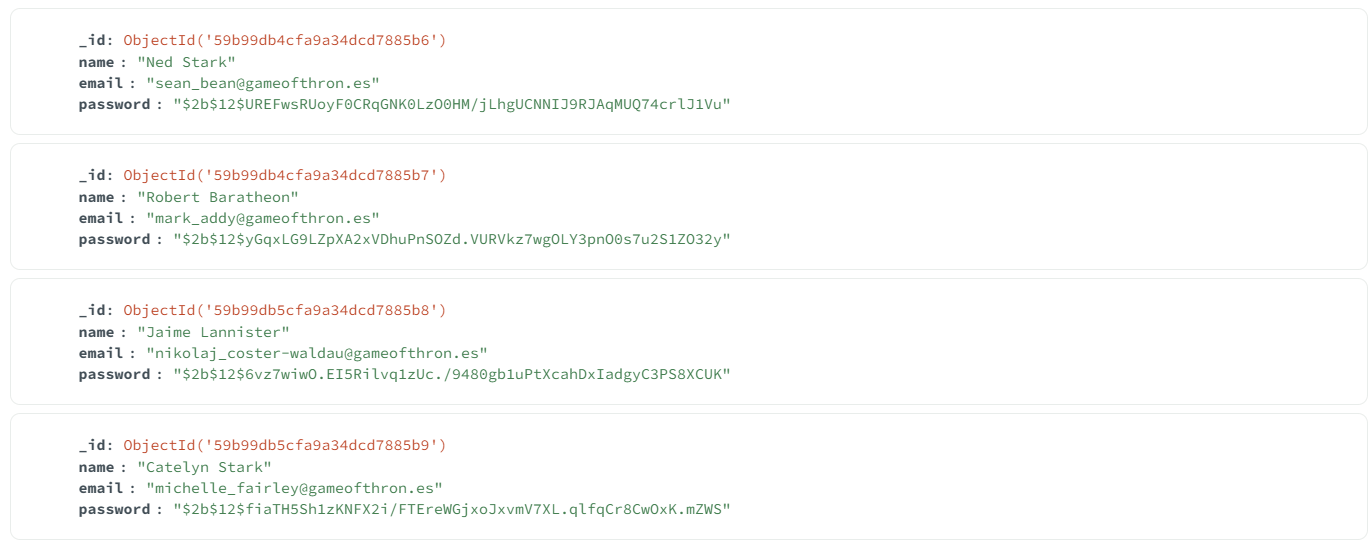
Example)

3️⃣MongoDB 아키텍처
MongoDB는 *분산형 데이터베이스로 동작하며, *수평 확장(Scale-out) 에 최적화됨
* 수평 확장 (Scale-out)
데이터베이스 성능을 높이기 위해 서버를 추가하는 방식
→ MongoDB의 경우, 샤딩을 통해 데이터를 여러 서버에 분산하여 저장하고, 복제를 통해 각 서버의 데이터를 안전하게 유지함
* 분산형 데이터 베이스 (Distributed Database)
데이터를 여러 서버(혹은 노드)로 나누어 분산 저장하고 처리하는 시스템
이를 통해서 단일 서버에서 처리할 수 있는 한계를 넘어서는 대규모 데이터 처리 및 성능 최적화가 가능해짐
MongoDB는 **샤딩과 복제를 통해 분산형 구조를 지원 → 성능과 **고가용성 제공
**샤딩 (Sharding)
분산형 데이터베이스의 핵심 기능 중 하나
데이터를 여러 서버(샤드)에 분배해서 저장하며, 각 샤드는 독립적으로 데이터를 관리하고 쿼리 처리를 함
샤딩을 통해, 데이터가 많아져도 성능 저하 없이 수평 확장이 가능. 이때 데이터 분배의 기준은 샤드 키(Shard Key)
→ MongoDB의 로드 밸런싱 공유 프로세스는 승인된 읽기 및 쓰기 처리량을 유지하면서 여러 가상 머신에 대규모 데이터 세트를 한번에 배포
**고가용성(High Availability)
시스템이 장애가 발생해도 서비스가 중단되지 않도록 하는 기능
○ Replica Set (복제 세트)를 사용해 여러 노드에 데이터를 복제하여 장애 발생 시 자동으로 대체 서버로 전환(Failover) 가능
○ Primary-Secondary 구조를 통해 데이터를 복제하고, 장애 발생 시 Secondary 노드가 Primary로 승격되는 구조 가짐
+----------------------------+
| Client (Driver) |
+----------------------------+
│
▼
+----------------------------+
| MongoDB Server |
+----------------------------+
│ │
▼ ▼
+------------+ +------------+
| Collection | | Collection |
+------------+ +------------+
● Client(클라이언트) -- MongoDB에 요청을 보내는 어플리케이션
● MongoDB Server(몽고DB 서버) -- 데이터를 저장하고 관리하는 중앙 엔진
● Collections(컬렉션) -- 여러 개의 Document를 저장하는 컨테이너
4️⃣ MongoDB 설치 및 데이터베이스 생성
● 몽고 디비 설치
https://www.mongodb.com/ko-kr/docs/manual/tutorial/install-mongodb-on-windows/
Windows 에 MongoDB Community Edition 설치 - MongoDB 매뉴얼 v8.0 - MongoDB Docs
설치 중에 MongoDB를 Windows 서비스로 구성하고 시작할 수 있으며, 설치가 성공적으로 완료되면 MongoDB 서비스가 시작됩니다. Install MongoD as a Service0}을 선택합니다.다음 옵션 중 하나를 선택합니다.Ru
www.mongodb.com
위의 URL로 들어가면 튜토리얼을 볼 수 있다
● 데이터베이스 생성
아니면 나와 같은 경우는 MongoDB Atlas의 클라우드 서비스를 이용하여 클라우드에 데이터베이스를 생성하였다. 이렇게 하면 직접 컴퓨터에 몽고디비를 설치하지 않아도 데이터베이스를 사용할 수 있다는 장점이 있다. 또한 mongoDB에서 제공하는 MongoDBCompass 프로그램을 사용하여 쉽게 데이터베이스를 관리할 수 있다.

화살표를 통해 들어가서 가입 혹은 로그인 후 들어가면

여기서 Cluster0은 MongoDB Atlas의 클라우드 서비스에서 제공하는 기본 클러스터이다. MongoDB Altas의 클러스터 안에서 데이터베이스를 생성 및 관리 할 수 있다. 즉, 클러스터는 데이터베이스를 포함하는 컨테이너 역할을 한다고 생각하면 된다.
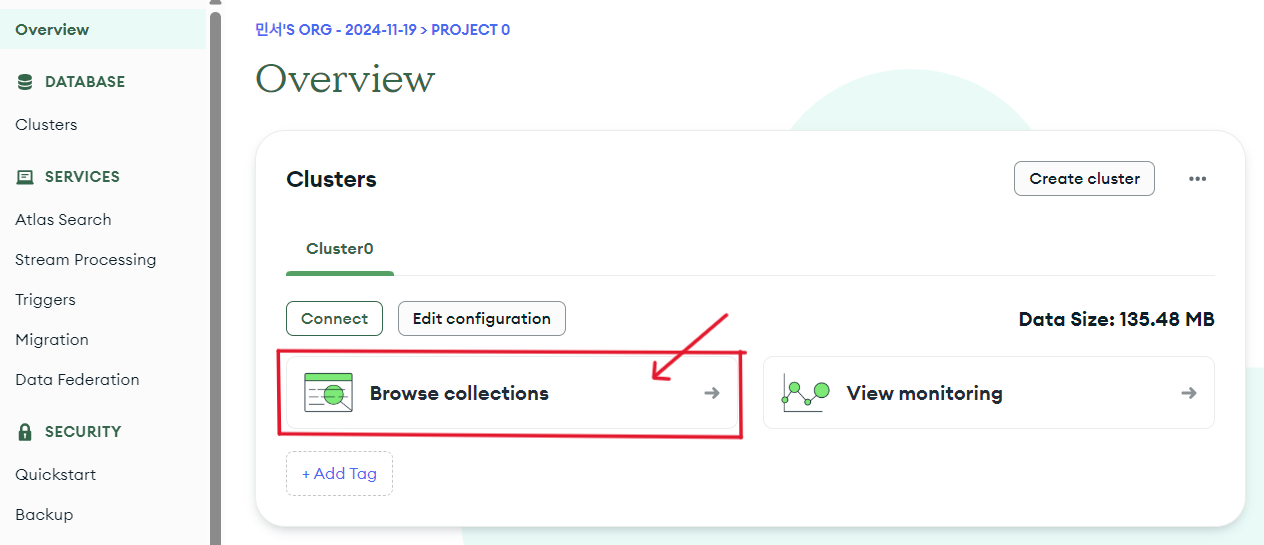
이렇게 목록으로 들어갔으면 아래 화살표 부분 ('Create Database')를 누르면 데이터 베이스가 새로 생성이 된다.
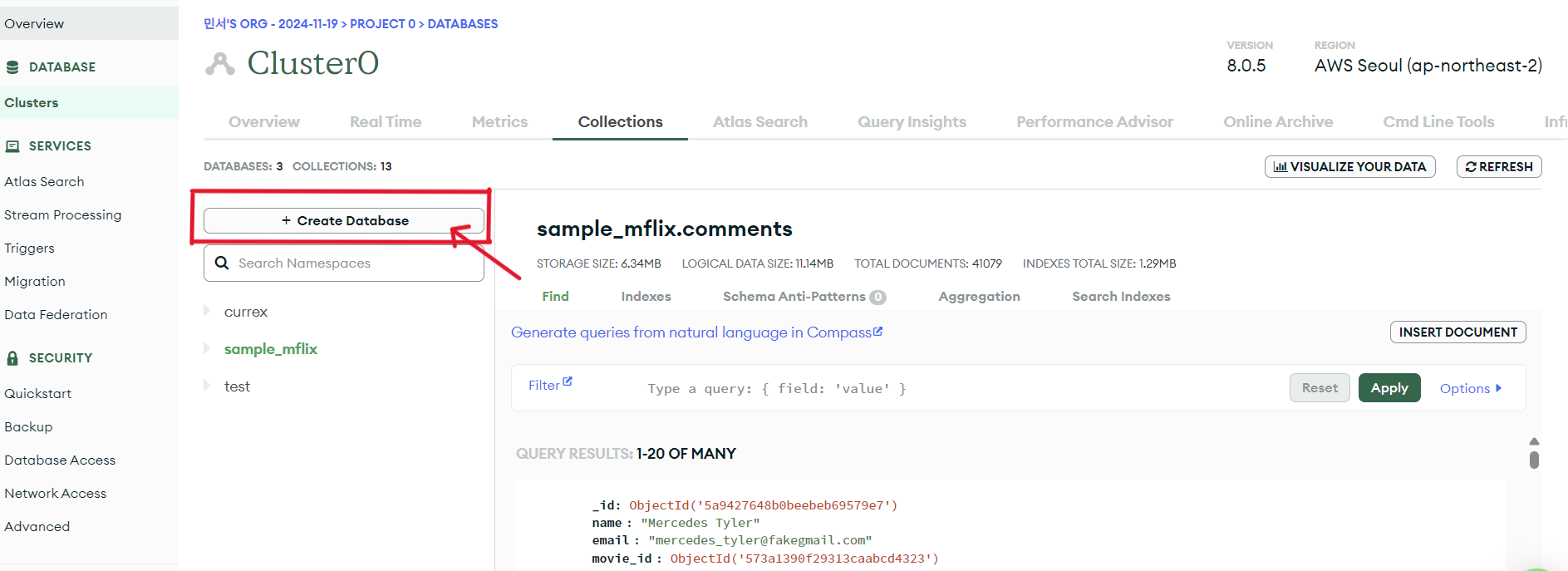

이 창에서 database name, collection name을 입력하고 create를 누르면 데이터베이스가 생성된다. additional preferences는 선택사항이다.
3️⃣Python 연동하기
* 참고 : python 실행환경은 ' pycharm ' 을 사용한다
이제 python 과 mongoDB를 연결해보도록 하겠다
● 먼저 pymongo 라는 라이브러리를 설치해준다
pymongo : 파이썬과 mongoDB를 연결해주는 라이브러리
○ pycharm 왼쪽 하단 터미널을 클릭하고 아래 명령어를 입력해준다
pip install pymongo
● Mongo Atlas로 들어가서 연결하려는 데이터베이스가 있는 클러스터의 python 연결 코드를 가져온다
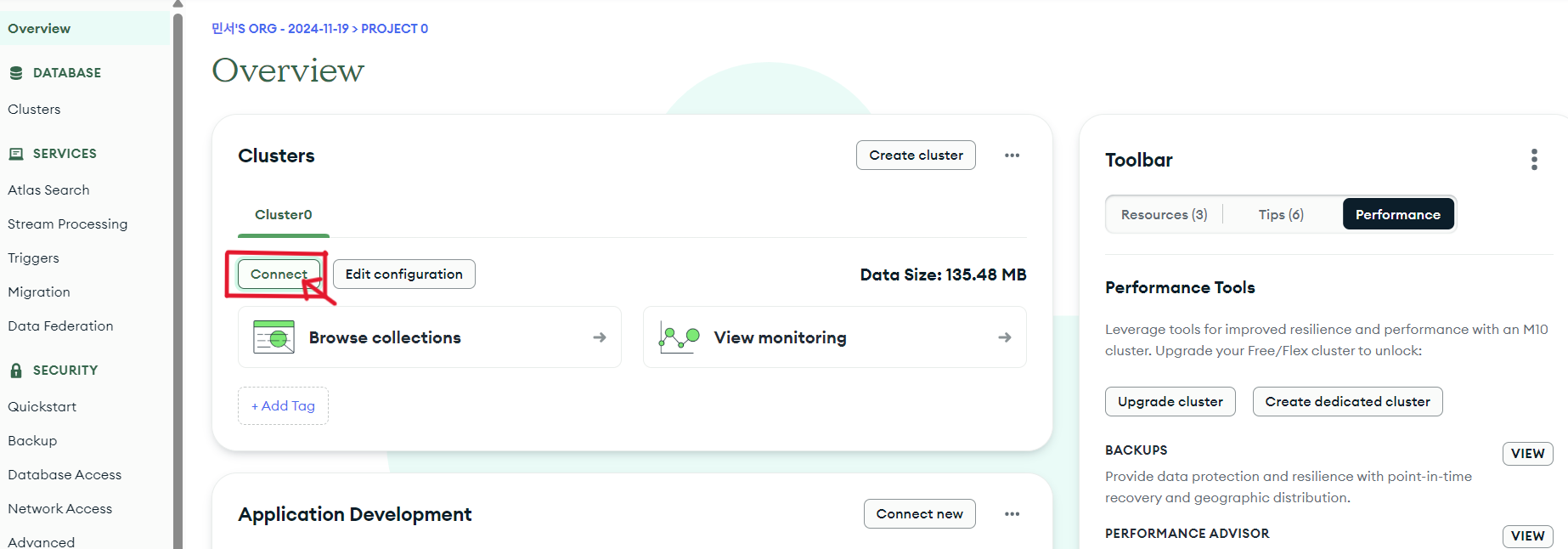
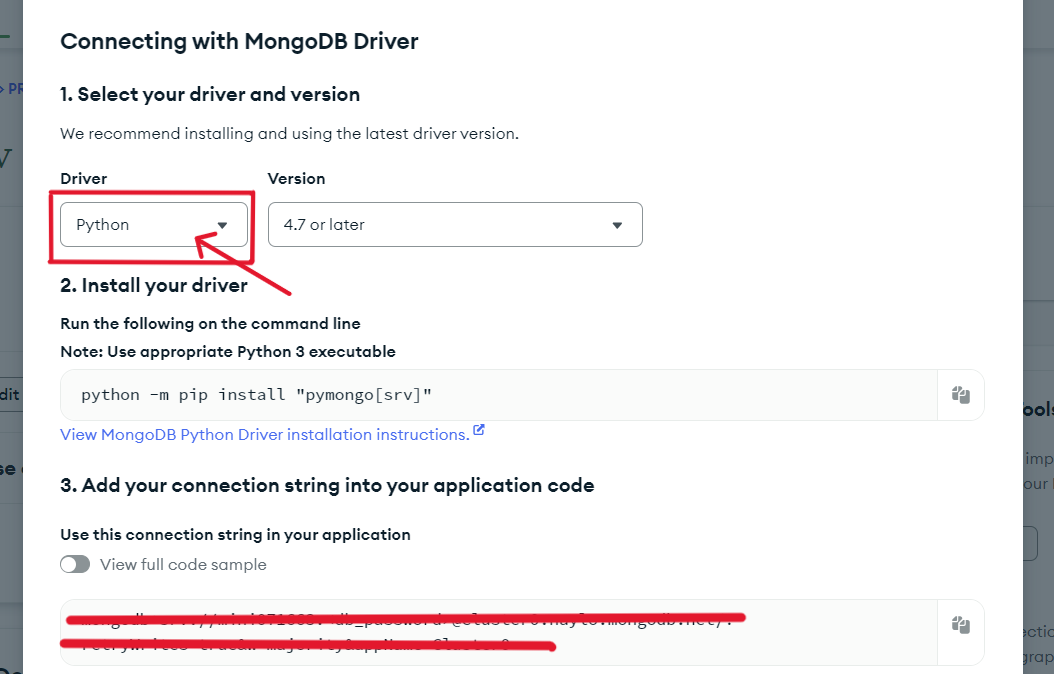
이제 pycharm 에 들어가서 아래의 코드를 입력하여 python과 연결을 수행해준다
from pymongo import MongoClient
# MongoDB 연결
MONGO_URI = "복사해온 connection string 입력"
#이때 db_password에 비밀번호를 넣어주면 됨. 특수문자 같은 경우에는 그대로 넣으면 안되고 변환해서 넣어줘야함 ex) @ = %40
client = MongoClient(MONGO_URI)
# 데이터베이스 선택
db = client.dataEngineering
# 컬렉션 선택
collection = db["name"]
# example 데이터 삽입
sample_data = {"name": "Alice", "age": 25, "city": "Seoul"}
collection.insert_one(sample_data)

4️⃣CRUD 만들기
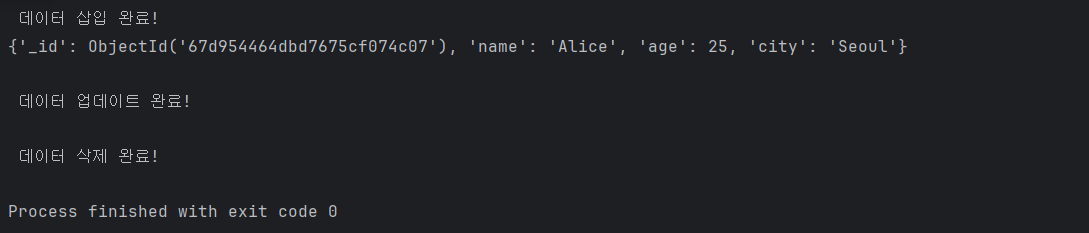
CRUD의 나머지도 수행해준다 (Read, Update, Delete)
# example 데이터 CRUD
# 삽입은 위에서 이미 진행완료(생략)
# 데이터 읽기
for user in collection.find():
print(user)
# 데이터 업데이트
collection.update_one({"name": "Alice"}, {"$set": {"age": 30}})
print("\n 데이터 업데이트 완료!")
# 데이터 삭제
collection.delete_one({"name": "Alice"})
print("\n 데이터 삭제 완료!")
이걸 실행시켜보면,,,,,
5️⃣ pymongo 함수 정리
● 데이터 삽입 (Create)
○ insert_one(document) : 단일 문서 삽입
○ insert_many([document1, document2, ...]) : 여러 개의 문서 삽입
● 데이터 조회 (Read)
○ find_one(filter) : 조건을 만족하는 첫 번째 문서 조회
○ find(filter) : 조건을 만족하는 모든 문서 조회
○ find( {}, {"field": 1} ) : 특정 필드만 선택하여 조회
○ count_documents(filter) : 조건을 만족하는 문서 개수 반환
● 데이터 업데이트 (Update)
○ update_one(filter, update) : 조건을 만족하는 첫 번째 문서 업데이트
○ update_many(filter, update) : 조건을 만족하는 모든 문서 업데이트
○ replace_one(filter, new_document) : 기존 문서를 새로운 문서로 교체
● 데이터 삭제 (Delete)
○ delete_one(filter) : 조건을 만족하는 첫 번째 문서 삭제
○ delete_many(filter) : 조건을 만족하는 모든 문서 삭제
● 기타
○ limit(n) : 조회할 문서 개수 제한
○ sort([("field", 1)]) : 정렬 (1: 오름차순, -1: 내림차순)
'기타' 카테고리의 다른 글
| NoSQL (0) | 2025.03.13 |
|---|---|
| 인컴상 - 과업 모델링 (0) | 2024.11.12 |
| 티스토리 글꼴 변경 절망편... (0) | 2024.06.19 |
| 이산수학 - 조건명제의 진릿값 : 전제가 F 일때 (0) | 2023.03.26 |